

Today in the talk: NetApp FabricPool.
Or: “Bridging (All-Flash) FAS systems with the hybrid cloud(s)”.
Introduction
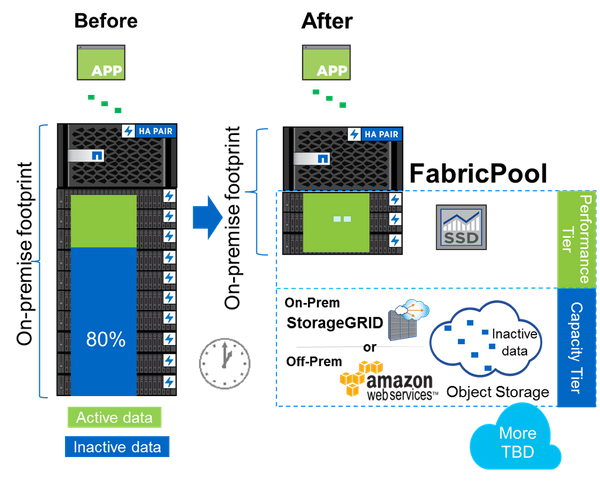
With NetApp FabricPool you can attach a S3 storage (NetApp StorageGRID, Amazon S3 or any other compatible) to an All-Flash FAS system and make it’s aggregates hybrid thereby. It could be used to move your cold data (i.e. snapshot data) to a less expensive storage pool and reduce your expensive all-flash footprint:
You can use FabricPool with all-flash systems, only. But if you have ONTAP Select, you can use your spinning drive aggregates, too. In the following article, I want to connect my ONTAP Select to my StorageGRID Cluster.
Using FabricPool, you have two types of tiers. The “performance tier”, which is your all-flash aggregate, and a “capacity tier”, which is your S3 pool.
You can configure four tiering policies to your volumes:
- none: keeps all data in your performance tier
- auto: applies to all data in your volume
- snapshot-only: applies only to snapshot data
- backup: applies only to DP data
Preparation
First of all, you may want to know, how much cold data could be moved to the capacity pool. You need to enable the “inactive data reporting” on the aggregate:
na-cl2-nbg6a::> aggr modify -aggregate aggr_na1a_ssd01 -is-inactive-data-reporting-enabled true
After that, you can have a look at the volumes on this aggregate:
na-cl1-nbg3::> volume show -fields performance-tier-inactive-user-data,performance-tier-inactive-user-data-percent
vserver volume performance-tier-inactive-user-data performance-tier-inactive-user-data-percent
------- ------ ----------------------------------- -------------------------------------------
vmware vol_vmware_data_nfs_sas01
335.8GB 16%
FabricPool Setup
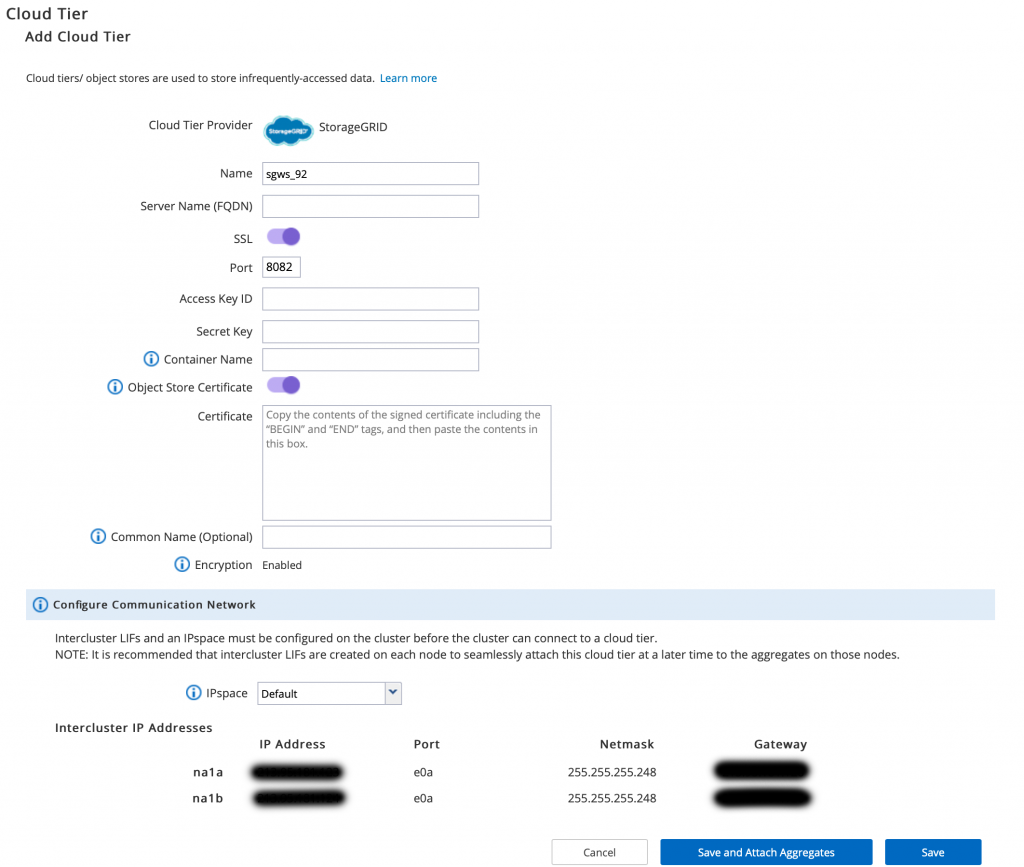
To setup the FabricPool, we need a new tenant and a bucket on the StorageGRID Cluster. In the NetApp ONTAP System Manager, we navigate to our aggregate(s) and add a cloud tier and attach it to our aggregate:
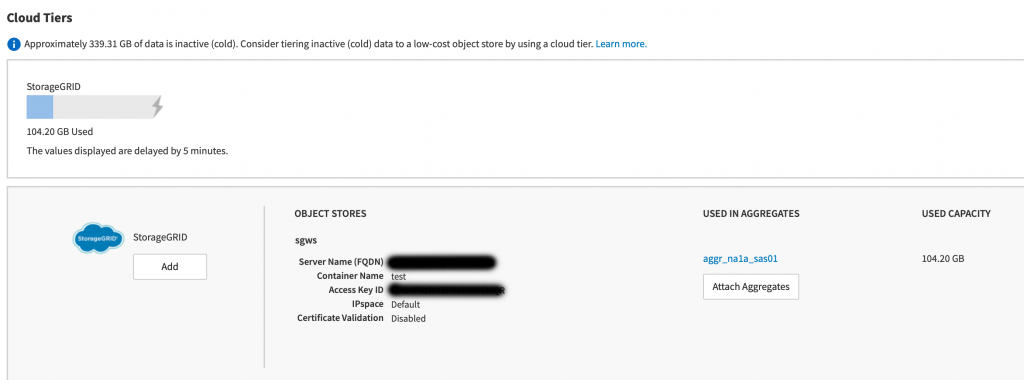
After successfully adding and attaching the cloud tier, we now have a hybrid cloud aggregate:
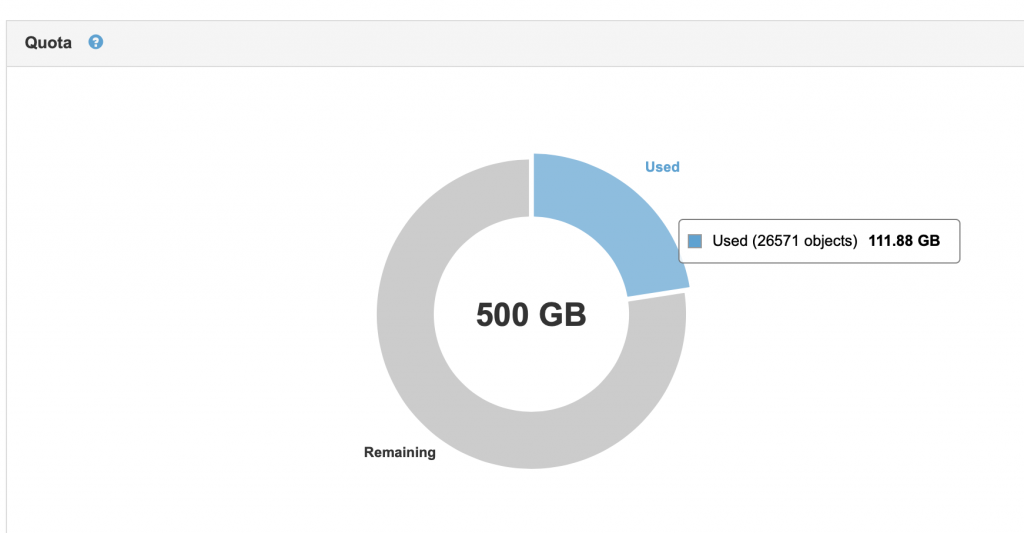
In the StorageGRID tenant GUI, you can see your used data:
Caution 1: there is a volume option “tiering-minimum-cooling-days” – the default is 31 days. Data will only be migrated after these days. And the inactive data reporting works only after these days, too.
Caution 2: data will only be migrated, if your aggregate has reached the fullness threshold:
na-cl1-nbg3::*> storage aggregate object-store show -fields tiering-fullness-threshold
aggregate object-store-name tiering-fullness-threshold
--------------- ----------------- --------------------------
aggr_na1a_sas01 sgws 10%